Designing robust data pipelines can be one of the slowest processes in data science development. It can also require maintenance of complex infrastructure. In this post we outline some useful MLOps tools that help with this process, and some good options for small teams.
Orchestration
Orchestration is the bread and butter of designing data pipelines. Orchestration tools configure how your data pipelines will run in production:
- What will trigger a data pipeline to begin (scheduled or based off e.g. data arriving).
- The order of your data pipeline and which processes trigger another.
Orchestration engines work using a DAG or directed acyclic graph. This means that each process will be a node in your graph, with arrows going from one node to another. The arrows determine which processes should follow another. This can be visualised graphically quite nicely, like in the picture below.
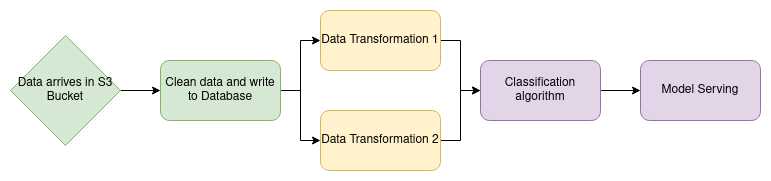
Example of a data pipeline DAG
There are many open source orchestration tools. The classic tools are airflow and luigi. Some newer orchestrators have been released since then, that can offer some slightly more modern features, though at the cost of a less developed community. These include: argo (has to be productionised on kubernetes) and dagster.
One problem with open source orchestration tools, is they need to be productionised and maintained on particular infrastructure (e.g. in the case of argo, this would be a kubernetes cluster). This can be a significant overhead for small data teams.
For smaller data teams an alternative option is out-of-the-box solutions. One popular option for this is to use AWS Step functions, and AWS batch; or similar services offered by other cloud providers. Because step functions are serverless, and AWS batch only boots up the EC2 when a job is running, these options can be cost effective. Alternatively, most out of the box, commercial data science platforms will have orchestrators built in.
ML Reproducibility and Deployment
The ML lifecycle is starting to become more defined, with experimentation performed on a local machine or cheap virtual machine in the cloud; the code is then refactored and deployed if the experimentation is successful.
The problem is that the refactoring and deployment step can take a long time if processes are not put in place.
This next set of tools I find particularly interesting. They aim to bridge the gap between experimentation and deployment and make it less painful. They do this by:
- Implementing pipelining tools that make it easier to deploy code on orchestrators.
- Model and data versioning and reproducibility to help keep track of experiments and easily deploy new models.
- Having data access and credentials tools which make it easier to change where data is kept (for example if data is moved from local storage, to S3, to a database).
Tools for this include: metaflow built by the Netflix team and designed to work seamlessly with AWS; mlflow a popular tool for model management; kedro a similar tool to metaflow but not as constrained to AWS infrastructure.